GraphX
Unifying Graphs and Tables
GraphX: Unifying Graphs and Tables
GraphX extends the distributed fault-tolerant collections API and interactive console of Spark with a new graph API which leverages recent advances in graph systems (e.g., GraphLab) to enable users to easily and interactively build, transform, and reason about graph structured data at scale.
Motivation
From social networks and targeted advertising to protein modeling and astrophysics, big graphs capture the structure in data and are central to the recent advances in machine learning and data mining. Directly applying existing data-parallel tools (e.g., Hadoop and Spark) to graph computation tasks can be cumbersome and inefficient. The need for intuitive, scalable tools for graph computation has lead to the development of new graph-parallel systems (e.g., Pregel and GraphLab) which are designed to efficiently execute graph algorithms. Unfortunately, these systems do not address the challenges of graph construction and transformation and provide limited fault-tolerance and support for interactive analysis.
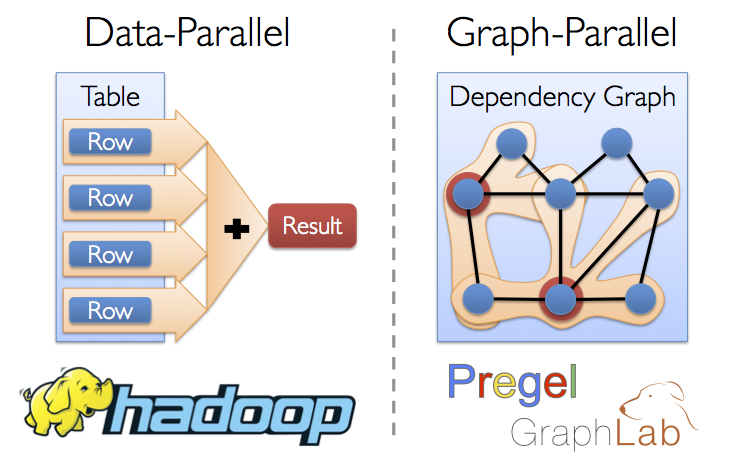
Solution
The GraphX project combines the advantages of both data-parallel and graph-parallel systems by efficiently expressing graph computation within the Spark framework. We leverage new ideas in distributed graph representation to efficiently distribute graphs as tabular data-structures. Similarly, we leverage advances in data-flow systems to exploit in-memory computation and fault-tolerance. We provide powerful new operations to simplify graph construction and transformation. Using these primitives we implement the PowerGraph and Pregel abstractions in less than 20 lines of code. Finally, by exploiting the Scala foundation of Spark, we enable users to interactively load, transform, and compute on massive graphs.
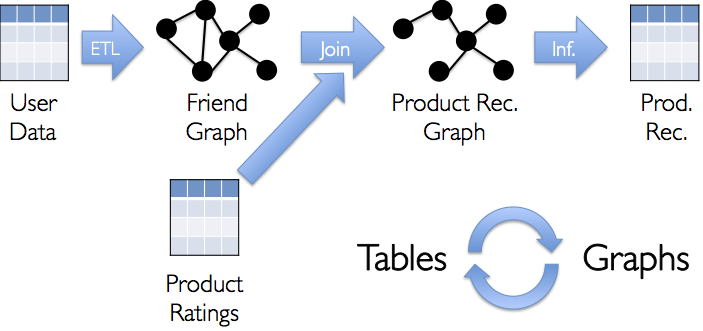
Examples
Suppose I want to build a graph from some text files, restrict the graph to important relationships and users, run page-rank on the sub-graph, and then finally return attributes associated with the top users. I can do all of this in just a few lines with GraphX:
// Connect to the Spark cluster
val sc = new SparkContext("spark://master.amplab.org", "research")
// Load my user data and prase into tuples of user id and attribute list
val users = sc.textFile("hdfs://user_attributes.tsv")
.map(line => line.split).map( parts => (parts.head, parts.tail) )
// Parse the edge data which is already in userId -> userId format
val followerGraph = Graph.textFile(sc, "hdfs://followers.tsv")
// Attach the user attributes
val graph = followerGraph.outerJoinVertices(users){
case (uid, deg, Some(attrList)) => attrList
// Some users may not have attributes so we set them as empty
case (uid, deg, None) => Array.empty[String]
}
// Restrict the graph to users which have exactly two attributes
val subgraph = graph.subgraph((vid, attr) => attr.size == 2)
// Compute the PageRank
val pagerankGraph = Analytics.pagerank(subgraph)
// Get the attributes of the top pagerank users
val userInfoWithPageRank = subgraph.outerJoinVertices(pagerankGraph.vertices){
case (uid, attrList, Some(pr)) => (pr, attrList)
case (uid, attrList, None) => (pr, attrList)
}
println(userInfoWithPageRank.top(5))
Online Documentation
You can find the latest Spark documentation, including a programming guide, on the project webpage at http://spark.incubator.apache.org/documentation.html. This README file only contains basic setup instructions.
Building
Spark requires Scala 2.9.3 (Scala 2.10 is not yet supported). The project is built using Simple Build Tool (SBT), which is packaged with it. To build Spark and its example programs, run:
sbt/sbt assembly
Once you've built Spark, the easiest way to start using it is the shell:
./spark-shell
Or, for the Python API, the Python shell (./pyspark).
Spark also comes with several sample programs in the examples
directory. To run one of them, use ./run-example <class>
<params>. For example:
./run-example org.apache.spark.examples.SparkLR local[2]
will run the Logistic Regression example locally on 2 CPUs.
Each of the example programs prints usage help if no params are given.
All of the Spark samples take a <master> parameter that is the
cluster URL to connect to. This can be a mesos:// or spark:// URL, or
"local" to run locally with one thread, or "local[N]" to run locally
with N threads.
A Note About Hadoop Versions
Spark uses the Hadoop core library to talk to HDFS and other
Hadoop-supported storage systems. Because the protocols have changed
in different versions of Hadoop, you must build Spark against the same
version that your cluster runs. You can change the version by setting
the SPARK_HADOOP_VERSION environment when building Spark.
For Apache Hadoop versions 1.x, Cloudera CDH MRv1, and other Hadoop versions without YARN, use:
# Apache Hadoop 1.2.1
$ SPARK_HADOOP_VERSION=1.2.1 sbt/sbt assembly
# Cloudera CDH 4.2.0 with MapReduce v1
$ SPARK_HADOOP_VERSION=2.0.0-mr1-cdh4.2.0 sbt/sbt assembly
For Apache Hadoop 2.x, 0.23.x, Cloudera CDH MRv2, and other Hadoop versions
with YARN, also set SPARK_YARN=true:
# Apache Hadoop 2.0.5-alpha
$ SPARK_HADOOP_VERSION=2.0.5-alpha SPARK_YARN=true sbt/sbt assembly
# Cloudera CDH 4.2.0 with MapReduce v2
$ SPARK_HADOOP_VERSION=2.0.0-cdh4.2.0 SPARK_YARN=true sbt/sbt assembly
For convenience, these variables may also be set through the
conf/spark-env.sh file described below.
When developing a Spark application, specify the Hadoop version by
adding the "hadoop-client" artifact to your project's
dependencies. For example, if you're using Hadoop 1.0.1 and build your
application using SBT, add this entry to libraryDependencies:
"org.apache.hadoop" % "hadoop-client" % "1.2.1"
If your project is built with Maven, add this to your POM file's
<dependencies> section:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>1.2.1</version>
</dependency>
Configuration
Please refer to the Configuration guide in the online documentation for an overview on how to configure Spark.
Contributing to GraphX
Contributions via GitHub pull requests are gladly accepted from their original author. Along with any pull requests, please state that the contribution is your original work and that you license the work to the project under the project's open source license. Whether or not you state this explicitly, by submitting any copyrighted material via pull request, email, or other means you agree to license the material under the project's open source license and warrant that you have the legal authority to do so.